Hey!
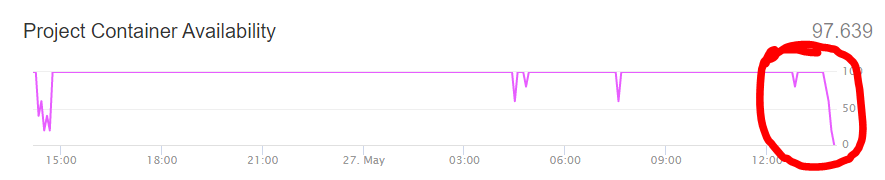
Glitch projects seem to be slow today, I believe it is because of lowered container status on status.glitch.com.
1 Like

lmaoo you beat me to the screenshot
1 Like
we sent the same thing at the same time lol
1 Like
recently been experiencing the same problem but mine says project not found
Yeah, same here. If you access it through a custom domain it’ll give you a 520 error though
1 Like
This even is a bit more odd than other outages. Normally projects will just show the endless loading screen with “maintenance” as the title.
My custom domain didn’t give me a 520 error, just very slow:
http://champs.biz/
DuckDuckGo seems to disagree with me lol

Also I took the screenshot too lol:

DuckDuckGo must have like 8g internet connection lol
seems to be coming back now

Glitch be like:

1 Like
Where can I get DuckDuckGo wifi? 
1 Like
? 
 ?
?


yay its back

I see the same numbers every week  520
520

Its back? Yes!!!
1 Like
Doesn’t cloudflare have something called Always Online that loads cached webpages when the server is down? I think that might be for paying users only


Yep. I just got an email too.
1 Like

“…because the server stopped responding”. Are we having so much users on the support because of this that we are causing an unintentional ddos attack. Discourse does have to ping the server like every 5 seconds to download new post updates.
1 Like
Oh great… Had downtime yeserday too
I’m pretty sure support.glitch.com uses discourse hosting. Check the links to images and you will notice they are hosted on aws.discourse-cdn.com
1 Like
Website is’t working
The community site uses Cloudflare (AWS).
support.glitch.com does use discourse.
The software and the hosting plan provided by discourse, yes. I don’t think they self host…
1 Like
They need to do something similar to how Discord Bots do sharding. So if a project container goes out, not all projects go offline - especially the paying users’ projects.
That would be a good idea, however that would probably make the amazon bill go through the roof. They would need to use at least twice as many VMs.
They could always select like a group of 10 to 50 containers to test deploys on before deploying on all other containers so we can limit problems.
3 Likes
True, but I feel like that would be the only good solution. /shrug
I’m also not really sure why the outages are happening…
It really shouldn’t be an upstream service because amazon has 99.99% uptime. Maybe its a code error internally? Or maybe they are matience.
1 Like
Why does that even happen?
1 Like
I did create an unintentional DDoS-kinda thing and Discourse returned a 429 after some time for “too many requests from this IP”. Turns it was a Firefox (on a bootable USB running Ubuntu) bug causing my page to refresh every 0.5 seconds.
Well it’s a bit better than ubuntu running on a full disk with 180gb worth of files in lost+found that I need to delete.
I’m in a kind of similar situation, Windows got corrupted and I need to wipe the whole disk.
Tried running Ubuntu on VMBox but had no luck.